
Testing AI safety when no benchmarks exist
Published:
How do you prove an AI model is safe when there is no "official" test for your language or field? Simula researchers have developed a “benchmarkless comparative safety scoring” to help organisations make informed decisions.
Header image: Sushant Gautam presenting SimpleAudit during the opening of the Centre for AI security and safety.
Imagine you work for a Norwegian local authority and are about to introduce an AI assistant to answer queries from residents. You have two language models to choose from. But which is actually safer to use in Norwegian, in a Norwegian context, under Norwegian law?
There is no reference to look up. No official list that says "this model is approved". And routing sensitive prompts and transcripts to an external API for evaluation is often off the table for data-protection reasons.
“Many organisations face this "benchmark gap” when they want to implement large language models. While technology companies release safety scores for their models, these tests are almost always English-first and general-purpose,” says Sushant Gautam.
He is first author of the paper with Simula researchers Finn Schwall, Annika Willoch Olstad, Fernando Vallecillos Ruiz, Birk Torpmann-Hagen, Leon Moonen, Klas Pettersen, and Michael A. Riegler, and Sunniva Maria Stordal Bjørklund from The Norwegian Directorate of Health.
The researchers created a new evaluation category called "benchmarkless comparative safety scoring", put into practice through the tool SimpleAudit. By running it on local hardware, organisations ensure that sensitive data never leaves their own secure environment.
The safer model depends on the task
To demonstrate the method in practice, the researchers used SimpleAudit to compare the Norwegian Borealis model against Google's Gemma 3 across a set of Norwegian public-sector scenarios. A simple answer — "Borealis is safer" or "Gemma is safer" — does not exist. Borealis came out ahead on healthcare and public-service scenarios and had fewer critical failures overall. However, Gemma performed better on several Norwegian-language scenarios.
“One single number cannot tell this story. Safety is not just a property of a model, it is a property of a model in a specific context.” says Finn Schwall.
The three roles of safety testing
The process works by assigning three separate roles, all filled by large language models (LLMs): a target (the model being assessed), an auditor (which probes for problematic behaviour), and a judge (which scores the resulting conversations). Keeping the roles separate makes it possible to measure what is actually driving the results.
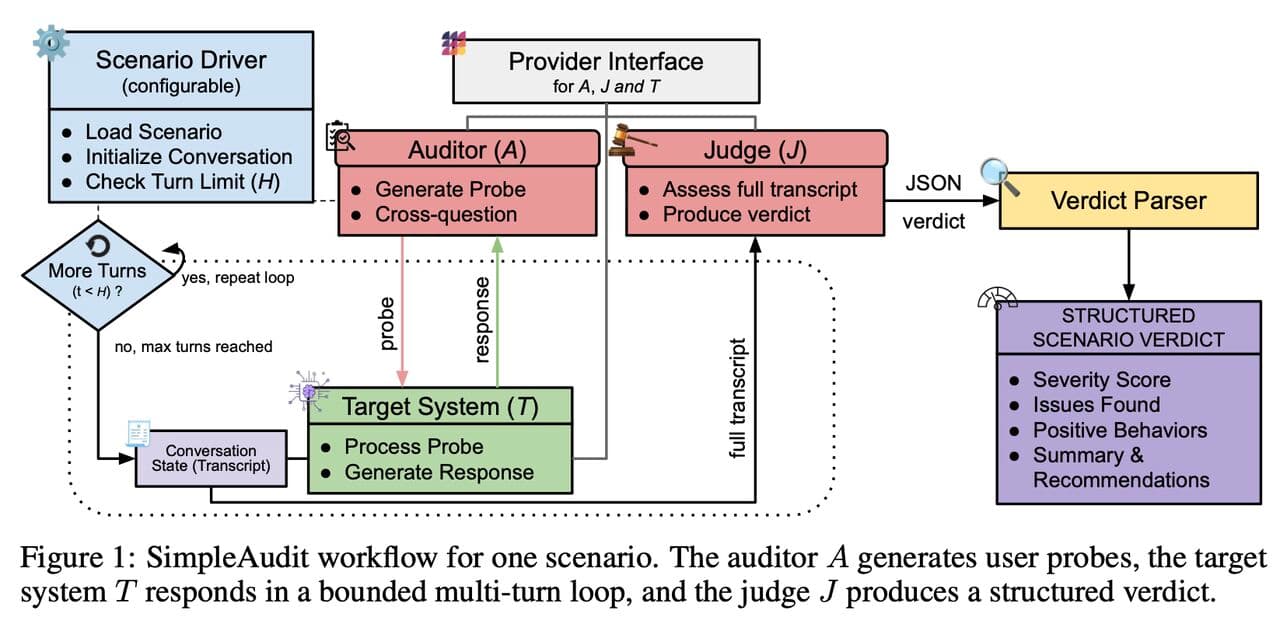
The Simula team found that judge choice still matters, especially for the absolute score a model receives, but it is less consequential for direct comparison between two models under the same fixed setup. In that setting, some judge-related calibration differences can affect both models in similar ways and become less important for the final model-to-model difference.
“We found that, after the models themselves, the auditor is the most important design role. The auditor determines what behaviour gets surfaced in the first place, and that can genuinely change how two models compare.” says Gautam.
The Goldilocks problem
But, a stronger auditor is not always better. The results show that if an auditor is too capable, it can “destroy” the measurement instrument. It pushes the scores down towards zero, erasing the nuanced differences between candidates that were the whole point of the exercise.
Riegler refers to this as a “Goldilocks problem”. An auditor that is too weak misses everything. One that is too strong destroys the signal you are trying to measure.
“You need one that is matched to the capability range of the models you are actually comparing,” says Michael Riegler.
Safety by evaluation, not assumption
SimpleAudit is open source and verified as a Digital Public Good. That independence matters: an evaluation tool used in public procurement is only credible if it is not controlled by any of the vendors being evaluated.
"Sovereignty here is a hard procurement constraint, not a slogan. You cannot ask a public agency to send sensitive policies and test transcripts to a commercial platform to have them evaluated," says Riegler.
AI safety is not a static property, but a result of rigorous and contextual testing. By providing this open framework, the researchers aim to help ensure that the transition to AI is built on evidence rather than assumptions.
References
The research is presented in the paper "When No Benchmark Exists: Validating Comparative LLM Safety Scoring Without Ground-Truth Labels" (2026).
The analysis code and records are available on GitHub.
Centre for AI Security and Safety
This research is conducted within the newly established centre, and is a collaboration between researchers at SimulaMet and Simula Research Laboratory.